本文翻译、整理自
本文讲解了Autograd——pytorch中用于自动求微分的模块。下面的内容不需全部掌握,但读一下还有有助于加强理解的。
在backward的过程中排除一部分子图
Tensor的属性requires_grad代表它是否需要求梯度。注意除了这个属性除了可以被显式地设置性之外,还会被一个规则所定义:
如果一个Tensor
A
A
由其他Tensor 计算得到,只要存在一个requires_grad值为True的
Bi
B
i
,
A
A
的requires_grad就是True。
这个属性可以用来”冻结“model的一部分使其参数不变,微调网络中的其他部分。比如下面这个例子中只调节最后的FCN:
model = torchvision.models.resnet18(pretrained=True) for param in model.parameters(): param.requires_grad = False # Replace the last fully-connected layer # Parameters of newly constructed modules have requires_grad=True by default model.fc = nn.Linear(512, 100) # Optimize only the classifier optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)Autograd怎样记录历史信息
从概念上来说,Autograd的对每个数据记录了一个有向无环图(DAG),叫做计算图,来表示它的计算过程。
比如下图表示的计算图。沿着计算图应用链式求导法则就可以求出梯度。 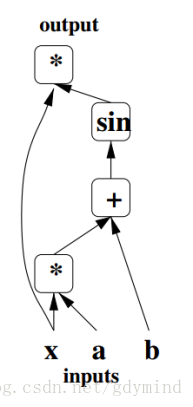
在底层实现中,PyTorch中的计算图的每个结点都是一个Function对象,这个对象可以使用apply()进行操作。
在前向传播过程中,Autograd一边执行着前向计算,一边搭建一个graph,这个graph的结点是用于计算梯度的函数,这些函数结点保存在对应Tensor的.grad_fn中;而反向传播就利用这个graph计算梯度。
Autograd中的in-place operations问题
在Autograd使用in-place operations相当麻烦,不建议使用==。Autograd对buffer的释放和使用已经很高效了,in-place operations大多数情况下都会让效果更差。
总的来说,限制in-place operations有以下两个原因:
1. in-place operations会改变一些值,可能导致梯度计算错误
2. 每个in-place operation后都必须更新计算图,因为要把Function对象的所有输入的creator都改变,万一别的
Tensor
T
e
n
s
o
r
也引用了相同内存区域就很麻烦。这时候PyTorch会报错。
In-place正确性检查
每个Tensor都有一个verion counter来记录对它的操作次数。当一个Function对象保存了它用于反向传播的若干Tensor时,它会将它们的version counter记录下来。当访问self.saved_tensors时,Pytorch会执行检查Tensor的counter,如果它比记录的counter要大就会报错。
这样就保证了,如果你使用了in-place functions并且没有看到报错,计算的梯度一定是正确的。